

보고 API는 안전한가요?
BigQuery에 저장된 모든 데이터는 미사용 시 및 전송 시 암호화됩니다. 이는 데이터가 Google 서버에 저장되거나 해당 서버와 클라이언트 간에 전송될 때 강력하게 암호화되어 보호된다는 의미입니다.
또한 BigQuery에는 사용자의 역할과 권한에 따라 데이터 액세스를 제한할 수 있는 액세스 제어 기능이 내장되어 있습니다. 이를 통해 데이터에 액세스할 수 있는 사람과 해당 데이터로 수행할 수 있는 작업을 정확하게 지정할 수 있습니다.
BigQuery는 또한 Auth 2.0 및 API 키와 같은 표준 메커니즘을 통한 인증 및 권한을 지원합니다.
Google의 인프라는 서비스 거부 공격, 데이터 침해, 무단 액세스 등 일반적인 위협으로부터 보호할 수 있도록 설계되어 방화벽, 침입 감지 시스템, 정기 보안 감사 등의 여러 보안 조치를 구현합니다. BigQuery API 또한 보안을 적극 고려한 설계로 항시 데이터가 보호될 수 있도록 다양한 보안 조치를 지원합니다.
데이터는 얼마나 자주 업데이트되나요?
매일 업데이트됩니다. 새로 고침은 UTC+0 자정에 시작되며 최대 업데이트 시간은 12시간입니다. 업데이트에는 전날 자정(UTC+0)까지 수신된 모든 데이터가 포함됩니다.
데이터는 어느 기간까지 지원되나요?
지정된 조직에 대해 승인된 모든 과거 데이터 기록을 사용할 수 있습니다.
직접 액세스 사용자인 경우 어떻게 연결하나요?
이미 GCP에 가입되어 있으므로 간단하게 사용할 수 있습니다. 로그인하여 UI 또는 API를 통해 관련 테이블을 쿼리하기만 하면 됩니다.
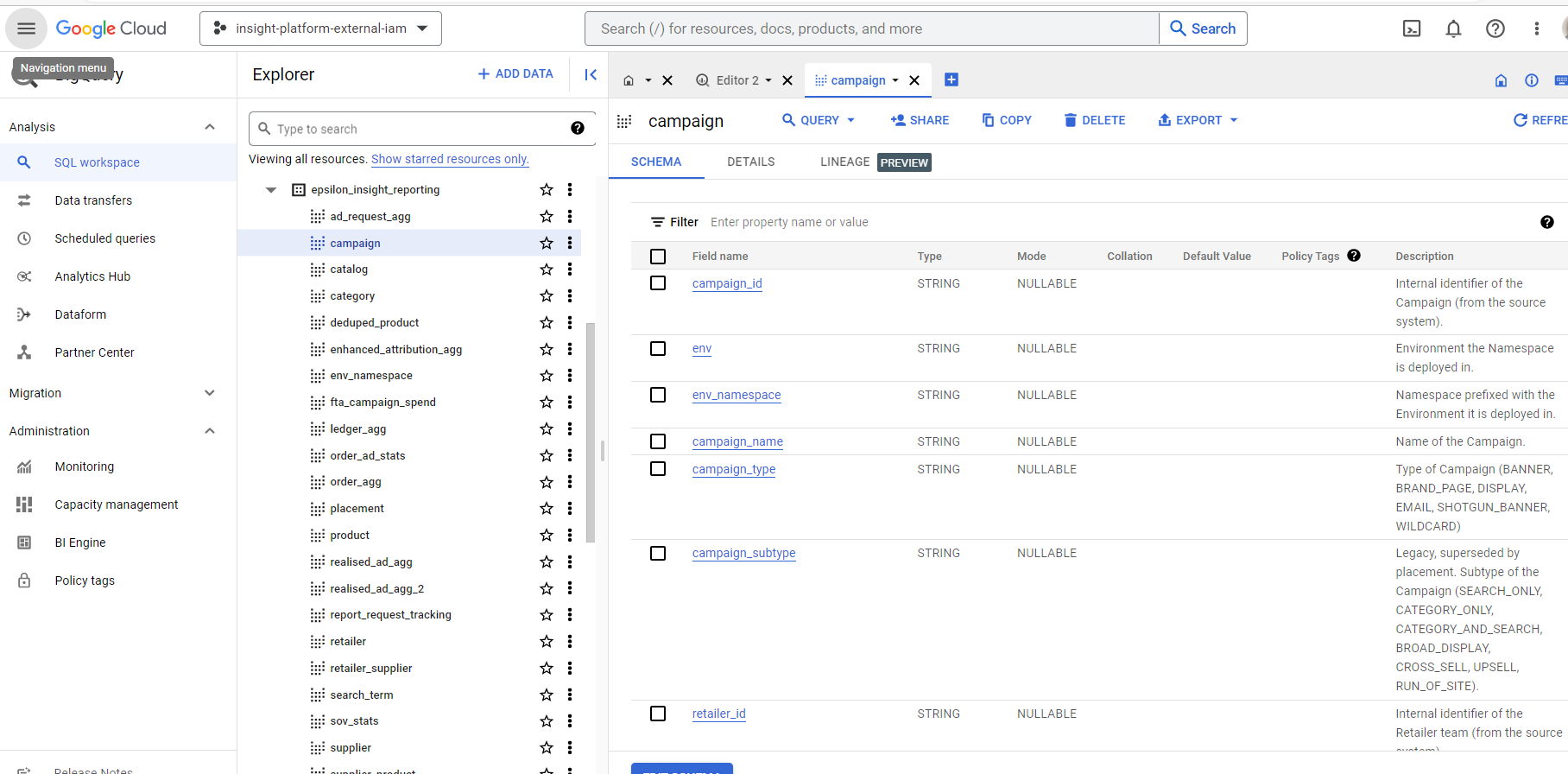
오류가 발생했습니다. "사용자에게 프로젝트 내 bigquery.jobs.create 권한이 없습니다" - 제가 무엇을 잘못하고 있는 걸까요?
귀하가 제공한 계정에 대해 CitrusAd는 관련 데이터 세트에 BigQuery 조회 권한을 부여했으며 이를 통해 귀하는 해당 데이터 세트 내 테이블을 읽을 수 있습니다. 프로젝트에서 이러한 원격 테이블을 실제로 쿼리하려면 몇 가지 작업이 필요합니다.
다음과 같은 상황을 가정해 보겠습니다:
- 귀하의 프로젝트 = "client-project-123456"
- Your user = [email protected]
- CitrusAd 데이터 세트: "insight-platform-external-iam.client_insight_reporting"
귀하는 다음을 수행해야 합니다:
-
Grant [email protected] the bigquery.jobs.create permission within the client-project-123456 project (not the CitrusAd project). You can do this by assigning the BigQuery Job User role.
-
When executing a query, you must run the query within your project (as you only have permissions to read the dataset within the CitrusAd project, not run queries within it). Here is how that might happen using a simple cloud shell command example (executing as [email protected]):
bq query --use_legacy_sql=false --project_id client-project-123456 'SELECT * FROM insight-platform-external-iam.client_insight_reporting.campaign limit 10;'클라이언트 프로젝트는 insight-platform-external-iam이 아닌 귀하의 프로젝트로 설정되어 있습니다.
사용하는 다른 도구에도 유사한 접근 방식을 취해야 합니다. 자세한 정보는 해당 도구의 설명서를 참조하시고, 팁은 GCP 온라인 설명서를 참조하십시오!
CitrusAd 데이터가 내 위치에 없습니다. 데이터를 내 위치로 가져오려면 어떻게 해야 하나요?
여러 방법 중 가장 쉬운 방법은 CitrusAd와 동일한 위치에 데이터 세트를 생성한 후 변환, 쿼리 등을 수행하여 해당 데이터 세트 내 테이블에 저장한 후 원하는 위치로 테이블을 복사하는 것입니다.

여러 방법을 통해 UI, BQ 명령줄 도구 및 API를 사용하여 위치 간에 복사할 수 있습니다. 자세한 내용은 Google Cloud 문서 페이지를 참조하십시오.
GCP API 사용자가 아닌 경우 어떻게 연결하나요?
CitrusAd에서 인증 메커니즘에 통합할 수 있는 JSON 형식의 관련 자격 증명을 제공합니다.
BigQuery UI가 아닌 보고 API만 사용하여 쿼리를 디버깅할 수 있나요?
예, BigQuery API에서 문제 발생 여부를 나타내는 코드를 반환하며 오류 메시지도 제공합니다.
쿼리 비용이 얼마나 들지 예측할 수 있습니까?
예, API에는 쿼리가 실행될 경우 스캔할 내용에 대한 바이트 추정치를 가져오는 메커니즘이 있습니다. 이 추정값에 쿼리 호출 빈도를 곱하여 할당량에 얼마나 근접하는지 파악할 수 있습니다.
더 자세한 사항은 GCP 문서에서 확인할 수 있습니다.
드라이런 쿼리 | BigQuery | Google Cloud
할당량 제한을 초과하면 어떻게 되나요?
CitrusAd 계약서에서 할당량을 확인할 수 있습니다. 별도로 명시되지 않은 경우 쿼리 데이터 스캔은 기본적으로 매월 10TB로 설정됩니다.
계약에 일일 최대 API 호출 수가 포함될 수 있습니다. 별도로 명시되지 않은 경우 API 호출은 기본적으로 하루 100회로 설정됩니다.
할당량(데이터 스캔 또는 호출 수)을 초과한 경우 사용 내역 확인을 위해 연락을 드립니다. 계약에 따라 초과 요금이 적용될 수 있습니다.
계약 조건(또는 기본 한도)을 벗어난 중대한 오용이 발생하는 경우 CitrusAd는 액세스를 일시 중지할 수 있는 권리를 보유합니다.
보고 API 사용의 예는 무엇인가요?
다음은 일반적인 방법을 사용한 몇 가지 예입니다.
Python용 Google SDK
이 예시는 다음과 같습니다:
- BigQuery에 연결
- 쿼리 실행
- 결과를 CSV로 스풀링
import google.cloud.bigquery as bq
import pandas as pd
bq_client = bq.Client.from_service_account_json("<REPLACE>.json")
job_config = bq.QueryJobConfig(allow_large_results=True)
query_job = bq_client.query(
'SELECT count(1) FROM insight-platform-external-iam.<REPLACE>_insight_reporting.campaign
LIMIT 1000', job_config=job_config)
df = query_job.to_dataframe(create_bqstorage_client=False)
df.to_csv(r"C:\Users\<REPLACE>\<REPLACE>.csv", index=False)
print("Run Complete")쿼리 실행 전 스캔된 바이트 등의 추정치를 알아볼 수 있는 다른 방법도 있습니다.
BigQuery 설명서를 참조하십시오.
GCP를 사용하지 않는 경우 환경 변수를 통해 JSON 자격 증명 파일을 참조할 수 있습니다.
Python용 일반 API
import csv
import requests
from google.oauth2 import service_account
PROJECT_ID = "insight-platform-external-iam"
DATASET = "<YOUR DATASET HERE>"
END_POINT = f"https://bigquery.googleapis.com/bigquery/v2/projects/{PROJECT_ID}/queries"
QUERY = f"""
SELECT supplier_id, campaign_id, sum(ad_spend) as ad_spend, sum(clicks) as clicks
FROM `{PROJECT_ID}.{DATASET}.realised_ad_agg`
WHERE ingressed_at BETWEEN '2022-09-01' and '2022-12-31'
group by 1,2
"""
def get_token():
# With service account
credentials = service_account.Credentials.from_service_account_file('./secrets/service-account.json')
scoped_credentials = credentials.with_scopes(['https://www.googleapis.com/auth/cloud-platform'])
# Do token request
def req( method, url, headers, body, **kwargs):
resp = requests.post(url, headers=headers, data=body)
return type('obj', (object,), {'data' : resp.text, 'status': 200})
scoped_credentials.refresh(req)
return scoped_credentials.token
def run_job(token):
resp = requests.post(
END_POINT,
json={
"query": QUERY,
"useLegacySql": False
},
headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {token}"
}
)
return resp.json()['jobReference']['jobId']
def get_query_results(job_id, token):
status_endpoint = f'{END_POINT}/{job_id}?location=australia-southeast1'
completed = False
while not completed:
response = requests.get(status_endpoint, headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {token}"
})
completed = response.json()['jobComplete']
data = response.json()
rows = data['rows']
columns = [c['name'] for c in data['schema']['fields']]
return rows, columns
def extract():
token = get_token()
job_id = run_job(token)
rows, columns = get_query_results(job_id, token)
with open('results.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(columns)
for row in rows:
writer.writerow([i['v'] for i in row['f']])
extract()Google Cloud가 아닌 AWS 등을 사용하는 경우에도 API를 인증하고 사용할 수 있나요?
예, 가능합니다. CitrusAd에서 서비스 계정 자격 증명을 제공해 드립니다. 신청서에 자세히 설명되어 있습니다. 다음은 예시입니다.
# TODO(developer): Set key_path to the path to the service account key
# file.
# key_path = "path/to/service_account.json"
credentials = service_account.Credentials.from_service_account_file(
key_path, scopes=["https://www.googleapis.com/auth/cloud-platform"],
)
token = credentials.token
# use the token to do the API calls
# ...
# headers: Bearer ${token}
# ...공유되는 각 데이터 세트의 위치를 어떻게 확인할 수 있나요?
이 API 호출은 각 데이터 세트의 위치를 알려줍니다.
GET https://bigquery.googleapis.com/bigquery/v2/projects/insight-platform-external-iam/datasets
{
"kind": "bigquery#datasetList",
"etag": "RLU1Ww9C5FdhlcIuRHjW0A==",
"datasets": [
{
"kind": "bigquery#dataset",
"id": "insight-platform-external-iam:acme_insight_reporting",
"datasetReference": {
"datasetId": "acme_insight_reporting",
"projectId": "insight-platform-external-iam"
},
"location": "australia-southeast1"
},
{
"kind": "bigquery#dataset",
"id": "insight-platform-external-iam:acme_acme_analytics",
"datasetReference": {
"datasetId": "acme_acme_analytics",
"projectId": "insight-platform-external-iam"
},
"location": "us-central1"
}
]
}알아두면 좋은 사항이 있나요?
일반적으로 데이터를 많이 사용하는 경우, 특히 집계되지 않은 데이터(요청/실현된 광고/주문/향상된 어트리뷰션 등)에 액세스할 수 있는 경우에는 테이블을 자체 데이터 웨어하우스에 복사(스테이징)한 다음 해당 복사본에 필요한 비즈니스 로직에 대한 쿼리를 구현하는 것이 가장 좋습니다.
사용량이 많지 않은 사용자는 테이블을 직접 쿼리하여 특정 결과를 얻을 수 있습니다.
원활한 작동을 위해 허용된 할당량 이하로 사용량을 유지하는 것이 중요합니다.
또한 각 쿼리는 최대 1GB까지 다운로드할 수 있으며 그렇지 않은 경우 오류 메시지가 표시됩니다. 매우 큰 용량의 다운로드가 필요한 경우 여러 개의 작은 쿼리(예: 일별 또는 공급업체별 데이터 하위 집합 등)를 실행하십시오.
적절한 SQL문을 작성하는 데 도움이 필요하면 어떻게 하나요?
작성한 쿼리를 지정하여 티켓을 제출하면 검토해 드리며 필요한 경우 다시 연락을 드립니다.
Pandas 패키지를 사용하기 위한 팁이 있나요?
Pandas는 가장 널리 사용되는 분석 도구 중 하나입니다. 사용하려면 pandas-gbq 및 pydata-google-auth 종속성을 설치해야 합니다.
아래 스니펫은 BigQuery 테이블에서 데이터를 읽는 방법에 대한 실제 예시입니다.
import pandas as pd
from google.oauth2 import service_account
credentials = service_account.Credentials.from_service_account_file('path/to/the/credential/file')
query = 'select * from project.dataset.table'
dat = pd.read_gbq(
query,
project_id='project_id',
credentials=credentials
)More information about the Pandas function can be found here.
PySpark 패키지를 사용하기 위한 팁 있나요?
Assuming you have a working PySpark environment, you need to provide the correct jar file for the BigQuery connector appropriate to your PySpark version. For instance, PySpark 3.2.* requires spark-3.2-bigquery-0.30.0.jar. The list of the jar files as well as practical code snippets and parameters can be found here.
아래 코드 스니펫은 쿼리를 실행하는 방법의 예입니다.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('BigNumeric').config('spark.jars', 'spark-3.2-bigquery-0.30.0.jar').getOrCreate()
spark.conf.set('credentialsFile', 'path/to/the/credential/file')
spark.conf.set('viewsEnabled', 'true')
spark.conf.set('materializationProject', 'yourMaterializationProject')
spark.conf.set('materializationDataset', 'yourMaterializationDataset')
query = 'select * from project.dataset.table'
df = spark.read.format('bigquery').option('query', query).load()
df.show()중요: viewsEnabled 매개 변수는 true여야 합니다.
보기 데이터는 bigquery.tables.create 권한이 필요한 경우 PySpark에서 읽기 전에 임시 테이블에 구체화됩니다. 따라서 사용자에게 쓰기 권한이 있는 MaterializationProject 및 MaterializionDataset를 제공해야 합니다.
쿼리에서 필터를 요구하는 오류가 발생하나요?
분할된 테이블의 경우 필터는 필수 사항입니다. 필터를 사용하지 않으면 아래와 같은 오류 메시지가 표시됩니다.
파티션 제거에 사용할 수 있는 열 'partitioned_column'에 대한 필터 없이 'dataset_id.table_id' 테이블을 쿼리할 수 없습니다
오류를 해결하기 위해서는 대상 범위를 포함하는 적절한 필터를 추가하면 됩니다.
-- this query returns all records available since yesterday
select
*
from
dataset_id.table_id
where
ingressed_at >= date_sub(current_date, interval 1 day)테이블이 분할된 열을 확인하려면(위 예시의 ingressed_at와 같이) 해당 테이블의 설명을 참조하십시오.
액세스 권한은 어떻게 요청하나요?
프로세스
티켓을 제출하고 자격 기준에 대해 서면으로 동의해야 합니다.
CitrusAd는 잠재적 후보 목록을 참고하여 필요한 액세스 및 보안 설정 수준을 식별하고 적용 가능한 할당량과 비용을 결정합니다.
자격 기준
보고 API 액세스 자격을 갖추려면 요청자는 다음 기준을 준수해야 합니다.
일반
- 후보자는 이미 소속되어 있거나 일반 액세스 권한을 가진 CitrusAD 네임스페이스 및 팀에 대한 데이터 액세스만 요청할 수 있습니다. 후보자는 다음 중 어떤 시나리오를 신청하는지 지정해야 하며 기존 액세스 권한을 증명해야 합니다.
- 환경 레벨(CitrusAD 플랫폼 전체 구현은 후보자 전용)
- 네임스페이스 레벨(후보자는 개별 네임스페이스 또는 네임스페이스 목록 내 소매업체와 공급업체의 모든 팀을 볼 수 있는 권한을 가짐)
- 특정 리테일러 팀 ID 또는 그룹 레벨
- 특정 공급업체 팀 ID 또는 그룹 레벨
- 또한 통합자는 특정 공급업체 팀 ID 또는 그룹 레벨과 사례별로 소매업체가 동의한 경우 전체 소매업체 제품 카탈로그에 액세스할 수 있습니다.
- 거래 사실 데이터는 일반 기준 1a 또는 1b에 적합한 후보자에게만 제공될 수 있습니다.
- 거래 사실 데이터가 기준을 충족하지 않는 후보자에게는 사전 집계된 사실 데이터에 대한 액세스만 제공됩니다. 데이터는 일일 요약으로 집계됩니다(집계 시간대: UTC+0).
- 일반 기준 1d에만 해당되는 후보자는 광고 요청 데이터(제공되는 실현된 광고 데이터와 반대)를 받을 수 없습니다. 제품 데이터는 사례별로 소매업체가 동의한 경우 소매업체 제품 카탈로그를 받을 수 있는 통합자를 제외하고 공급업체가 실현된 광고에서 광고하는 특정 제품에 대해 제공됩니다.
- 차원 데이터에는 해당 레코드의 현재 버전만 포함됩니다. 후보자는 필요에 따라 과거 변경 사항 추적을 구현해야 합니다.
- 데이터는 매일 업데이트되며 수신이 완료된 UTC+0일 데이터가 12:00 UTC+0까지 업데이트됩니다.
- 후보자는 기본적으로 액세스가 읽기 전용이라는 것을 이해하고 있어야 합니다. API는 어떤 목적으로도 데이터 웨어하우스에서 개체를 생성하는 데 사용될 수 없습니다.
- 다른 데이터 소스와의 혼합은 후보자 자체 환경에서 이루어져야 합니다.
- 후보자는 Google BigQuery API 액세스 시 사용할 수 있는 SDK(또는 이와 동등한 것)가 있어야 합니다.
- 후보자는 SQL에 대한 전문 지식이 충분해야 합니다.
- 지원자는 CitrusAd 개념에 잘 알고 있어야 하며 그렇지 않은 경우 고객 지원 관리자 또는 기술 계정 관리자에게 표준 제품 교육을 받을 수 있도록 준비해야 합니다.
- 제공된 문서를 기반으로 후보자는 자체 솔루션을 개발할 것으로 예상됩니다. 설명서대로 SQL이 작동하지 않는 문제가 발생하면 일반 지원 채널을 통해 티켓을 제출해야 하며 제출 시 다음 정보를 제공해야 합니다.
- 연결할 계정
- 호출되는 정확한 SQL
- 표시된 오류 메시지에 대한 자세한 설명
- 후보자가 소매업체인 경우 전체적인 광고 라이프사이클을 파악할 수 있도록 CitrusAD 플랫폼에 노출 수/클릭 수/주문 정보를 제공해야 합니다.
- CitrusAD는 스키마를 변경할 수 있는 권한을 보유합니다. 이러한 변경은 일반적으로 기존 테이블과 보기에 새 열을 추가하는 것을 포함하며 이전 버전과 호환됩니다. 후보자는 와일드카드 등을 사용하는 대신 열 이름을 지정하도록 SQL을 구성해야 합니다. 변경 사항이 열 또는 테이블 사용 중단을 포함하는 경우 CitrusAd는 변경 사항을 구현하기 최소 12주 전에 알림을 보내며 알림은 플랫폼 사용자에게 제공되는 표준 릴리스 커뮤니케이션을 통해 제공됩니다.
후보자가 반드시 기존 Google Cloud Platform(GCP) 사용자여야 하는 것은 아니지만 GCP 사용자 여부에 따라 추가 기준이 적용됩니다.
GCP 외 후보자
별도의 합의가 없는 경우 CitrusAd는 후보자에게 CitrusAd 환경 내 단일 서비스 계정에 대한 자격 증명을 제공합니다.
별도의 합의가 없는 경우 다음과 같은 기본 조건이 적용됩니다.
- 일일 데이터 호출 수 최대 100회
- No more than 10TB of data scans per month (note, the API has a way of estimating the query scan size prior to execution, refer to Google documentation Dry run query | BigQuery | Google Cloud).
- GCP 외 후보자가 기준 1 및/또는 2를 초과하는 경우 CitrusAd는 단독 재량으로 액세스를 일시 중지할 수 있는 권리를 보유합니다.
- 개별 API 호출은 한 번에 1GB 이상의 데이터를 다운로드할 수 없습니다.
서비스 계정 파일을 디코딩하려면 어떻게 해야 하나요?
서비스 계정 자격 증명은 안전한 전송을 위해 base64로 인코딩된 형식으로 제공됩니다. 사용하기 전에 이 파일을 디코딩해야 합니다. 다음은 파일을 디코딩하는 방법의 예시입니다.
bash 사용:
# Replace encoded-credentials.txt with the file containing your base64 encoded credentials
base64 -d encoded-credentials.txt > service-account.jsonPython 사용:
import base64
# Replace encoded_credentials with your base64 encoded string
with open('encoded-credentials.txt', 'r') as f:
encoded_credentials = f.read()
decoded_credentials = base64.b64decode(encoded_credentials)
with open('service-account.json', 'wb') as f:
f.write(decoded_credentials)디코딩이 완료되면 귀하는 이전 예시와 같이 BigQuery 클라이언트 라이브러리와 함께 사용할 수 있는 service-account.json 파일을 얻게 됩니다.
GCP 후보자
별도의 합의가 없는 경우 후보자는 CitrusAd가 필요한 액세스 권한을 할당할 수 있도록 5개 이하의 GCP 계정에 대한 CitrusAd 세부 정보를 제공해야 합니다.
계정에 BigQuery 작업 사용자 역할(roles/bigquery.jobUser)이 할당되어 있어야 합니다.
다음 제한 사항이 적용됩니다.
- 일일 데이터 호출 수 최대 100회
- GCP 후보자가 기준 1을 초과하는 경우 CitrusAd는 단독 재량으로 액세스를 일시 중지할 수 있는 권리를 보유합니다.
- 개별 API 호출은 1GB 이상의 데이터를 다운로드할 수 없습니다.
용어집
환경
CitrusAd 플랫폼이 배포되는 물리적 환경의 이름입니다. 각 하나 이상의 네임스페이스를 호스팅합니다.
네임스페이스
CitrusAd 솔루션 구현의 일부인 모든 엔터티를 논리적으로 그룹화한 것으로 팀 및 팀이 소유한 모든 개체가 포함됩니다. 일반적으로 네임스페이스는 소매업체(팀), 다수의 공급업체(팀) 및 각 팀과 기타 관련 구성(소매업체 소유 카탈로그, 공급업체 자체 캠페인 구성 등)의 사용자로 구성될 수 있습니다. 팀(및 팀이 소유한 것)은 단일 네임스페이스에만 속합니다(팀은 여러 네임스페이스에 존재할 수 없음).
사용자
CitrusAd 시스템 내 사용자의 고유 식별자입니다. 하나의 이메일에 여러 개의 사용자 ID가 있을 수 있습니다. 각 userId는 네임스페이스별로 고유합니다. 각 사용자는 이름, 성, 이메일, 아이디를 가지며 CitrusAd 플랫폼에서 여러 팀의 팀원이 되어 여러 팀에 액세스할 수 있습니다.
팀
CitrusAd 시스템 내 팀으로 공급업체(광고주) 또는 소매업체일 수 있습니다. 공급업체 팀은 일반적으로 캠페인을 만들고 소매업체는 캠페인 검토 및 관리 기능을 수행합니다. CitrusAd 시스템의 사용자는 여러 팀의 팀원이 될 수 있으며 한 팀의 팀원만 될 수도 있습니다. 팀에는 일반적으로 관련된 사용자, 캠페인 및 지갑이 있습니다.
공급업체
CitrusAd 시스템 내 공급업체 팀입니다. 공급업체는 일반적으로 브랜드 모기업 또는 개별 브랜드별 일련의 팀일 수 있으며 캠페인을 유지하고 지갑 잔액 등을 관리합니다.
소매업체
CitrusAd 시스템 내 소매업체 팀입니다. 대부분의 네임스페이스에는 하나의 소매업체 팀만 있습니다. 소매업체는 일반적으로 제품 카탈로그를 유지 및 관리하고 캠페인 등을 검토합니다.
캠페인
특정 제품에 대한 배치 및 타기팅 전략으로 구성된 고유한 단일 캠페인입니다. 예를 들어 CitrusAd 시스템의 캠페인에서 최대 입찰가 0.60달러로 검색어 '초콜릿'을 타깃으로 한 제품 A와 B를 홍보할 수 있습니다. 일반적으로 한 팀에 여러 개의 캠페인이 있습니다.
카탈로그
CitrusAd 시스템 내 고유한 소매업체의 제품 카탈로그입니다. 소매업체는 일반적으로 단일 네임스페이스에서 하나의 제품 카탈로그만 CitrusAd와 동기화합니다. 카탈로그에는 소매업체 카탈로그의 모든 제품 목록, 이름, 브랜드, 카테고리 및 CitrusAd 시스템에 수집되는 기타 관련 속성이 있습니다.
제품
CitrusAd 시스템 내 단일 고유 제품입니다. 제품에는 제품 카탈로그에서 동기화된 고유한 제품 코드가 있으며 제품에는 카테고리, 분류, 브랜드 등과 같은 속성이 있을 수 있습니다.
지갑
CitrusAd 시스템의 지갑에는 결제 목적으로(예: 실현된 광고비 지불) 광고주의 자금이 저장됩니다. 각 지갑에는 단일 통화 코드가 있으며 동일한 통화 코드의 카탈로그에 대해서만 지출할 수 있습니다. 지갑은 팀 소유이며 팀은 여러 개의 지갑을 가질 수 있습니다. 지갑을 보관할 수 있습니다. 지갑을 보관하면 보관된 지갑의 크레딧을 계속 사용하면서 플랫폼에서는 지갑을 표시하거나 숨길 수 있습니다.
원장
CitrusAd 시스템에서 거래로 이어진 이벤트의 원장으로 스폰서 제품 또는 배너 광고에 대한 노출 또는 클릭과 같은 가장 일반적인 광고 이벤트입니다(데빗 발생). 이는 공급업체의 잔고(크레딧)에 대한 충전 및 조정이 될 수 있으며 각 이벤트에는 스폰서 제품, 배너 광고, 충전과 같은 '이유'가 있습니다.
요청
CitrusAd 시스템에 대한 광고 요청입니다. 요청에서 소매업체는 게재위치뿐 아니라 고객의 sessionId 또는 필터와 같은 요청과 관련된 컨텍스트도 지정합니다. 요청에 따라 CitrusAd는 관련 광고 유형(예: 카테고리 또는 검색어)의 광고를 소매업체에 다시 전송하여 고객에게 렌더링합니다.
(실현) 광고
광고는 고객에게 제공하기 위해 소매업체로 다시 전송되는 단일 광고 이벤트입니다. 소매업체가 최소한 광고가 노출되었다는 확인(광고가 실제로 실행되었다는 명시적 확인)을 반환하면 실현된 광고가 됩니다. CitrusAd 시스템에서 제공되는 모든 광고에는 고유한 단일 이벤트에 대한 참조인 고유한 실현 광고 ID가 있습니다.
카테고리
카테고리는 소매업체 사이트에서 '베이커리', '유제품'과 같이 웹사이트 분류에 속하는 페이지입니다. 소매업체는 일반적으로 카테고리 페이지에 광고를 요청하고 CitrusAD에 요청 시 이러한 관련 속성을 지정합니다. CitrusAd가 해당 카테고리에 활성화되어 있고 유효한 캠페인이 있는 경우 광고가 반환됩니다.
검색어
고객이 소매업체 웹사이트에 검색어를 입력하면 해당 검색어가 CitrusAd로 전송되어 관련 광고를 요청합니다. CitrusAd가 해당 카테고리에 활성화되어 있고 유효한 캠페인이 있는 경우 광고가 반환됩니다.
주문
소매업체 시스템에서 CitrusAd와 동기화된 고유한 주문입니다. 단일 주문에는 여러 orderItems이 포함될 수 있습니다(고객이 장바구니에 여러 상품을 담을 수 있는 것과 유사함). 고객의 주문이 완료되면 이 주문은 CitrusAd로 전송되어 CitrusAd 속성이 강화되며 그렇게 되면 ROAS(광고 수익) 및 기타 중요한 KPI를 소매업체와 광고주에게 제공할 수 있습니다.
어트리뷰션
어트리뷰션은 CitrusAd 시스템에서 운영되는 프로세스로 제출된 주문에 대해 고객에게 제공되는 광고를 할당합니다. 일반적인 고객 여정은 고객이 광고를 보고(노출) 광고를 클릭하여(클릭) 장바구니에 추가한 후 해당 상품을 구매하는(전환) 것입니다. 주문은 고객이 클릭한 고유 광고에 어트리뷰션됩니다. CitrusAd 시스템에서 주문이 어트리뷰션되려면 광고와 상호 작용(통합에 따라 보거나 클릭)해야 하며 고객이 광고와 관련된 상품을 구매해야 합니다. CitrusAd는 일반적으로 'sessionId'를 사용하여 주문을 광고에 어트리뷰션하며 소매업체는 광고 여정의 모든 관련 터치포인트에 'sessionId'를 지정합니다. 이를 통해 CitrusAd는 단일 고객에게 제공된 단일 광고가 특정 주문으로 이어졌음을 식별합니다.
날짜
모든 데이터는 집계 시 UTC+0 표준 시간대로 변환됩니다.
상한선
CitrusAd 플랫폼 구현 시 소매업체가 실제 노출되는 것보다 더 많은 광고를 요청하는 경우가 많습니다. 분석적인 관점에서 볼 때 이는 특정 지표의 실제 성과에 대해 정확하지 않은 노출 수를 제공할 수 있습니다.
예를 들어 광고 20개(AdType=Product)에 대한 요청이 있었고 플랫폼이 이에 대한 응답으로 광고 2개를 실행한 경우 요청에 대한 '충족률'은 10%(20개 중 2개)입니다. 하지만 실제로 광고가 4개만 사용(실현)될 가능성이 높다고 판단했다면 충족률은 50%(4개 중 2개)가 될 것입니다.
이러한 이유로 보고 내에는 한도라는 개념이 있습니다.
한도는 소매업체별로 설정되며 하나는 제품 광고에 다른 하나는 배너 광고에 적용됩니다(제품 광고 요청은 일반적으로 배너보다 훨씬 더 많은 광고를 요청하고 사용하기 때문).
예를 들어 소매업체의 제품 한도 = 4인 경우 요청 지표는 다음과 같이 보고됩니다.
NumAdRequests = 1
NumAdsRequested = 20
CappedNumAdsRequested = 4
NumAdsServed = 2
CappedNumAdsServed = 2
참고: 광고가 5개 실행된 경우(즉 광고 개수가 한도를 초과한 경우) 마지막 2개의 지표는 다음과 같이 보고됩니다.
NumAdsServed = 5
CappedNumAdsServed = 4 (한도 내로 조정)
한도는 필수 사항은 아닙니다. 한도가 지정되지 않은 경우 한도가 적용된 결과와 적용되지 않은 결과는 동일합니다.
향상된 어트리뷰션
CitrusAd 플랫폼은 어트리뷰션 섹션(위 참조)에 설명된 대로 어트리뷰션을 수행합니다.
보고 하위 시스템은 소매업체에 따라 다른 어트리뷰션 시나리오를 감지하고 플래그를 지정할 수 있습니다(향상된 어트리뷰션).
시나리오는 다음과 같습니다.
- 뷰 스루 어트리뷰션 노출 수
- 주문이 동일한 세션 ID에서 동일한 제품에 대해 조회된 광고로 어트리뷰션되었습니다(즉 클릭이 아니라 노출).
- 헤일로 클릭 어트리뷰션
- 주문이 동일한 세션 ID에서 동일한 헤일로 레벨에 속하는 제품에 대해 클릭된 광고로 어트리뷰션되었습니다. 가장 일반적인 헤일로 레벨은 브랜드입니다(즉 광고 제품과 주문 제품은 다르지만 동일한 브랜드에 속함). 구현에 따라 다른 헤일로 유형도 가능합니다. 예를 들어 헤일로는 더 구체적일 수 있으며 광고와 주문은 공통 브랜드뿐 아니라 공통 카테고리를 가진 제품에 대한 것이어야 합니다. 카탈로그에서 제품별로 설정된 소매업체 분류는 헤일로에서 이 추가 세부 수준을 정의하는 데 사용됩니다.
Version: 1ace13f